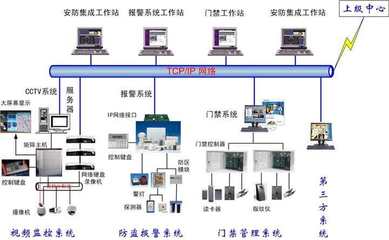
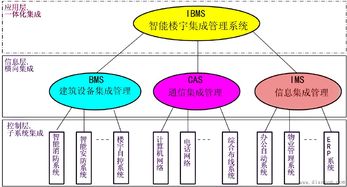
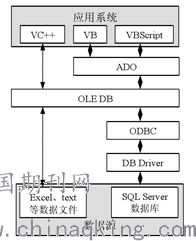
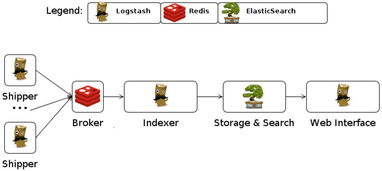
隨著信息技術的快速發(fā)展,大數(shù)據(jù)技術在各行各業(yè)的應用日益廣泛,而數(shù)據(jù)采集作為大數(shù)據(jù)系統(tǒng)中的關鍵環(huán)節(jié),其產(chǎn)品架構設計直接決定了數(shù)據(jù)獲取的效率、可靠性與擴展性。本文將結合網(wǎng)絡工程背景,對大數(shù)據(jù)系統(tǒng)數(shù)據(jù)采集產(chǎn)品的架構進行深入分析。數(shù)據(jù)采集產(chǎn)品的架構通常分為數(shù)據(jù)源層、采集層、傳輸層和存儲層。數(shù)據(jù)源層涉及各類數(shù)據(jù)源,如傳感器、日志文件、數(shù)據(jù)庫和網(wǎng)絡流量等,這些數(shù)據(jù)可能結構化或非結構化。在采集層,產(chǎn)品通過代理、API或直接連接方式收集數(shù)據(jù),例如使用Flume代理采集日志數(shù)據(jù),或通過Kafka連接器獲取實時數(shù)據(jù)流。網(wǎng)絡工程在這其中扮演重要角色,確保數(shù)據(jù)采集過程中的網(wǎng)絡傳輸穩(wěn)定、低延遲和高吞吐量。傳輸層負責將采集的數(shù)據(jù)從源端安全傳輸?shù)酱鎯蛱幚硐到y(tǒng),常采用消息隊列(如RabbitMQ、Kafka)或專用協(xié)議(如HTTP、FTP)實現(xiàn)。網(wǎng)絡工程優(yōu)化包括負載均衡、數(shù)據(jù)壓縮和加密,以應對大規(guī)模數(shù)據(jù)傳輸?shù)奶魬?zhàn)。存儲層將數(shù)據(jù)落地到分布式文件系統(tǒng)(如HDFS)或數(shù)據(jù)湖中,為后續(xù)處理提供支持。整體架構需考慮可擴展性、容錯性和實時性,以滿足不同業(yè)務場景需求。在實際應用中,大數(shù)據(jù)采集產(chǎn)品架構還需結合網(wǎng)絡工程原則,如拓撲設計、帶寬管理和安全策略,確保系統(tǒng)高效運行。通過合理的架構設計,大數(shù)據(jù)采集產(chǎn)品能夠實現(xiàn)高效、可靠的數(shù)據(jù)獲取,為大數(shù)據(jù)分析奠定堅實基礎。
大數(shù)據(jù)系統(tǒng)數(shù)據(jù)采集產(chǎn)品的架構分析
更新時間:2026-06-19 16:28:37
如若轉載,請注明出處:http://m.tiandai888.cn/product/21.html
PRODUCT
產(chǎn)品列表